リレーショナルデータベース(RDB)とは、データを表形式(テーブル)で管理し、行と列で構成されるデータベースで、テーブル同士を「関係(リレーション)」で結びつけて、複雑なデータを効率的に検索・操作できるシステムです。SQL(Structured Query Language)という標準言語で操作し、データの整合性(正確性や一貫性)が保ちやすいため、企業の基幹システムなどで広く利用されています。
この章では、リレーショナルデータベースの動作を実践的に確認するために、SQLiteのコマンドラインツールを使います。Mac OSでは標準でSQLiteがすでにインストールされています。(/usr/bin/sqlite3)
コマンドラインツールを起動するには、コマンドプロンプトを起動したあとで 、次のように実行して下さい。ツールが起動し引数に指定したデータベースに接続します。下の例では"learning.db"というデータファイルが作成されます。
> sqlite3 learning.db sqlite> .databases main: /Users/kuyamakazuhiro/Seminar/database/learning.db r/w sqlite>
4.1 テーブルの設計(物理設計)
テーブル
リレーショナルデータベースでは、表(テーブル)を作り、ここにデータを格納します。
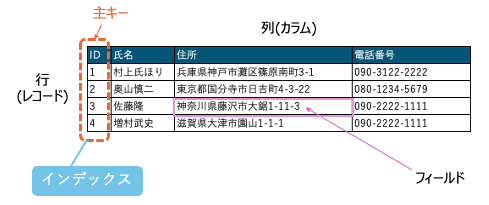
テーブルは以下の特徴を持っています。
- 行(レコード)と列(カラム)で表現されるデータ構造を持っています。また、レコードを構成する1つ1つの要素のことを「フィールド」と呼びます。
- テーブルの中には、「主キー(プライマリーキー)」と呼ばれる、行を一意に識別するために利用する列を一つ設定する必要があります。
- 主キーには、「インデックス」と呼ばれる、指定されたデータを素早く検索・抽出するための索引の機能を果たすものが付与されます。(通常、主キーに対しては自動的にインデックスが生成されます)
SQLiteを使って、このテーブルを作って、確認してみます。以下のようになります。
sqlite> CREATE TABLE members(id INTEGER PRIMARY KEY, name STRING, address STRING, phone STRING);
sqlite> .tables
members
さらに、このテーブルにデーターを入れて確認してみます。以下のようになります。
sqlite> INSERT INTO members(id, name, address, phone)
...> values(1, '村上しほり', '兵庫県神戸市灘区篠原南町3-1', '090-3122-2222'),
...> (2, '奥山慎二', '東京都国分寺市日吉町4-3-22', '080-1234-5678'),
...> (3, '佐藤隆', '神奈川県藤沢市大鋸1-11-3', '090-2222-1111'),
...> (4, '増村武史', '滋賀県大津市園山1-1-1', '090-2222-1111');
sqlite> select * from members;
1|村上しほり|兵庫県神戸市灘区篠原南町3-1|090-3122-2222
2|奥山慎二|東京都国分寺市日吉町4-3-22|080-1234-5678
3|佐藤隆|神奈川県藤沢市大鋸1-11-3|090-2222-1111
4|増村武史|滋賀県大津市園山1-1-1|090-2222-1111
表とリレーション
例えば、以下のようなExcelなどで作った帳票があったとします。
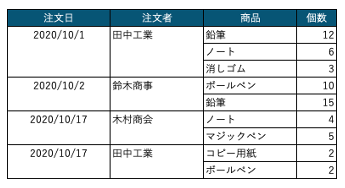
このようなデータをリレーショナルデータベースで表現するにはどうしたら良いでしょう?
リレーショナルデータベースでは一つのフィールドには一つの値のみを格納するのが原則です。また、レコードを一意に特定できる主キーとなるカラムも必要です。1フィールドに1つの値となるようにするならば、次のように表現することもできます。
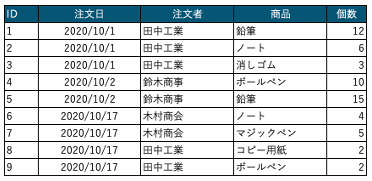
しかし、これだと「注文」という単位でデータを取得、検索するのが難しくなりますし、そもそも何の表なのかもよくわかりません。そこで、表を2つに分け、2つの表を「リレーション」でつなぎます。

こうすると、「注文」を表すテーブルと、「注文内容の詳細」を表すテーブルという具合に「責務」ごとに分割したテーブル構成にすることができます。
さらに、「注文」テーブルの「注文者」と「注文内容詳細」テーブルの「商品」に着目します。同じ値が何回も出てくるのがわかると思います。このような繰り返しがあるところも別テーブルにした方が、データーが扱いやすくなります。

このように複数の表をリレーションで繋いでデータ構造を表現するのがリレーショナルデータベースです。
ここまで見てきた表の分割の考え方は、データの重複(冗長性)をなくし、データの整合性(正確性・一貫性)を高めるものです。このようにテーブルを分割・整理する設計プロセスのことを、データベースの用語では「正規化」と言います。
SQLiteを使って、これらのテーブルを作るには、以下のSQL文を実行します。
CREATE TABLE orders(id INTEGER PRIMARY KEY, date TEXT, customer_id INTEGER);
CREATE TABLE order_details(id INTEGER PRIMARY KEY, order_id INTEGER, product_id INTEGER, quantity INTEGER);
CREATE TABLE customers(id INTEGER PRIMARY KEY, name STRING);
CREATE TABLE products(id INTEGER PRIMARY KEY, name STRING);
INSERT INTO customers(id, name) values(1, '田中工業'),(2,'鈴木商事'),(3,'木村商会');
INSERT INTO products(id, name) values(1,'鉛筆'),(2,'ノート'),(3,'消しゴム'),(4,'ボールペン'),(5,'マジックペン'),(6,'コピー用紙');
INSERT INTO orders(id, date, customer_id) values(1, '2020-10-01',1),(2,'2020-10-02',2),(3,'2020-10-17',3),(4,'2020-10-17',1);
INSERT INTO order_details(id, order_id, product_id, quantity) VALUES(1,1,1,12),(2,1,2,6),(3,1,3,3),(4,2,4,10),(5,2,1,15),(6,3,2,4),(7,3,5,5),(8,4,6,2),(9,4,4,2);
このように分割したテーブルの情報から、情報をまとめて取り出す場合にはSQLではJOIN演算子を使います。以下は、注文テーブルと顧客テーブルを結合して取り出す例です。
sqlite> SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id;
1|2020-10-01|1|1|田中工業
2|2020-10-02|2|2|鈴木商事
3|2020-10-17|3|3|木村商会
4|2020-10-17|1|1|田中工業
この場合、2つのテーブルの全てのカラムを取り出すことになります。取り出すカラムを限定したい場合は、以下のようにします。
sqlite> SELECT orders.id, orders.date, customers.name FROM orders JOIN customers ON orders.customer_id = customers.id;
1|2020-10-01|田中工業
2|2020-10-02|鈴木商事
3|2020-10-17|木村商会
4|2020-10-17|田中工業
課題:全てのテーブルを結合して、以下のような結果を取り出すにはどうすれば良いでしょう?
アンチパターン
データベースのテーブル設計には「アンチパターン」としてよく知られている、やってはいけない設計パターンがいくつかあります。代表的なのは以下で、これをやるとデータベースは非常に保守しづらくなってしまいます。
- 一つのカラムに複数の意味を持たせてしまっている
- 一つのレコードに同じ意味の属性が複数存在する(例:電話番号1、電話番号2、電話番号3….)「マルチカラムアトリビュート」をやってしまっている

4.2 トランザクションデータとマスターデータ
システムで扱うデータは、トランザクションデータとマスターデータに分けられます。
トランザクションデータ
業務に伴って発生した出来事の詳細を記録したデータ。日々、追加・更新が発生する
マスターデータ
業務活動に関連する共通概念を抽象的に表現することにより、その活動に意味を与えるデータ。例えば、勘定科目表、顧客識別子、製品識別子、組織情報など。追加・更新の頻度は少ない。
4.1の例で言うと、2つのテーブルがトランザクションデータ、2つがマスターデータとなります。

4.3 トランザクション
トランザクションとは、データベースに対する 1 つ以上の更新をまとめて行う単位のことです。
特定の処理をするにあたって、複数の更新(INSERT / DELETE / UPDATE)を同時にしなければいけない場面は多くあります。例えば、以下を途中で中断されたり、失敗したりするとデータの整合性が取れなくなってしまいます。
- 口座 A から ¥10,000 を引き落とす
- 口座 B に ¥10,000 を入金
それを防ぐためののものがトランザクションです。トランザクションは複数の更新処理をまとめたもので、すべて成功するか、すべて失敗する(取り消される)ようにする仕組みを持ちます。
トランザクション処理を実行するSQL文は以下の通りです。(SQLiteの場合)
| BEGIN TRANSACTION | トランザクションの開始 |
| COMMIT TRANSACTION | 変更を確定して、トランザクション処理を終了する |
| ROLLBACK TRANSACTION | 変更を取消して、トランザクション処理を終了する |
以下は、変更が成功したのでこれを確定してデータベースに反映する場合のサンプルコードです。
sqlite> CREATE TABLE sample(id INTEGER UNIQUE,name TEXT,age INTEGER);
sqlite> BEGIN TRANSACTION;
sqlite> INSERT INTO sample VALUES(1,"TANAKA",25);
sqlite> INSERT INTO sample VALUES(2,"YAMADA",30);
sqlite> COMMIT TRANSACTION;
sqlite> SELECT * FROM sample;
┌────┬──────────┬─────┐
│ id │ name │ age │
├────┼──────────┼─────┤
│ 1 │ 'TANAKA' │ 25 │
├────┼──────────┼─────┤
│ 2 │ 'YAMADA' │ 30 │
└────┴──────────┴─────┘
次に、変更が失敗してロールバックする場合のサンプルコードです。
sqlite> CREATE TABLE sample(id INTEGER UNIQUE,name TEXT,age INTEGER);
sqlite> BEGIN TRANSACTION;
sqlite> INSERT INTO sample VALUES(1,"TANAKA",25);
sqlite> INSERT INTO sample VALUES(1,"YAMADA",30);
Runtime error: UNIQUE constraint failed: sample.id (19)
sqlite> ROLLBACK TRANSACTION;
sqlite> SELECT * FROM sample;
┌────┬──────────┬─────┐
│ id │ name │ age │
├────┼──────────┼─────┤
└────┴──────────┴─────┘
SQLiteの場合、トランザクションを明示的に指定しなければ、SQL文が実行されるたびに、その変更が自動的にデータベースに反映(コミット)されます。(auto commitと言います)
4.4 データベースの性能
性能の劣化する原因
元々リレーショナルデータベースは、その仕組み上、高速にデータを検索することができる反面、データ生成と削除には時間がかかります。従って、頻繁にデータの生成と削除を繰り返すことが必要なシステムには、あまり向いていません。また、一つのテーブルに頻繁に挿入、消去を繰り返すことで、性能が劣化していくことがあります。これについて少し詳しく説明していきます。
リレーショナルデータベースは単なるデータテーブルの集合ではなく、検索性能を高速化したり、データの整合性を保証するために、その内部に以下の仕組みを備えています。

インデックス テーブルの中の目的のレコードを効率よく取得するための「索引」に相当するものです。テーブル内の特定のレコードを識別できる値(キー値)と、レコードのデータが格納されている位置を示すポインタで構成され、高速に検索するために「Bツリー」「B+ツリー」などの木構造になっています。
トランザクションログ トランザクションというのは、一連の操作を一つの論理的な処理単位としてまとめ、処理の完了を保証する仕組みのことです。処理が完了する前に、どこかのステップで一つでも失敗すると、全ての操作を全て元に戻しデータの整合をとることができ、これを「ロールバック」と呼びます。このロールバック処理や障害発生時にバックアップからのリストアを行う際に利用するために、発生したトランザクションと変更内容を記録したものがトランザクションログです
データの挿入や削除が行われると、その度にインデックスの更新とトランザクションログへの記録が行われる仕組みとなっており、その際にディスクI/Oが発生します。ディスクI/OにはメモリへのI/Oの約千倍近くの時間がかかりますので、メモリ上で処理ができる参照の処理に比べると、データ挿入、更新時、削除の処理には圧倒的に時間がかかり、頻繁に行われると性能が落ちます。
さらに、挿入、更新時、削除の処理が頻繁に行われると、以下の理由で徐々に性能が劣化していきます。

インデックスのバランスが崩れる 更新処理の多くなると,時間の経過と共にインデックスのノードのバランスが崩れ,ノードの深さが深くなってしまうことがあります。インデックスのノードが深くなるとディスクI/Oの回数が増え,性能が劣化します。
データが断片化する 更新処理の多いと、時間の経過と共にレコードの格納状態が悪化し、データの断片化(フラグメンテーション)が進行します。データの断片化が進行すれば,テーブルのレコード数が変わらなくてもブロック数が増えることがあり、ブロック数が増えればディスクI/Oが増え、これにより性能が劣化します。
防止策
ディスクI/Oの性能はかなり向上していますが、それでも極力ディスクI/Oが発生しないように設計するのがセオリーです。
- 一つのテーブルに多数のインデックスを つけないようにする。(検索を早くするために色々なカラムに安易にインデックスをつけてしまうと、その分ディスクI/Oが多く発生する。)
- データの挿入、更新、削除はできるだけまとめて行い、同じレコードを何度も挿入、削除するようなことは避けるようにする。
性能劣化への運用時の対策としては、インデックスや、データテーブルを定期的に再構築(再編成)することが挙げられます。これにより、インデックス崩れやデータの断片化が解消できますが、通常再構築をするためにはその間データベースシステムを停止させる必要があります。その間システムが使えなくなりますので計画的な運用が必要です。最近のハイエンドなデータベースシステムの中には、システム停止せずに再編成できるものもありますが、全てのテーブルの再編成できるわけではなく、それなりに制約がありますので注意が必要です。